![[logo]](/images/SimplyGenius.png)
Simply Genius .NET
Software that makes you smile
Check Help ( CHM ) Links Tool

|
|
Publicly recommend on Google
|
Note: You will need the MSHTML library if you have only installed the .NET redistributable, not the SDK (or VS).
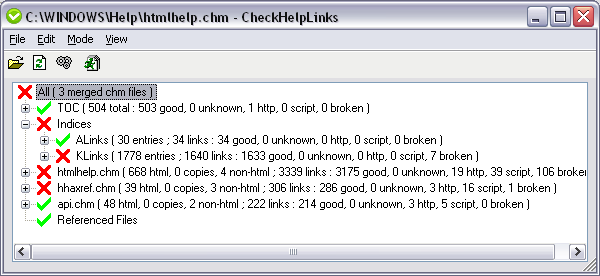
Introduction
This article presents a tool for checking links in help ( CHM ) files, including merged files. The app checks links in indexes, tables of contents, and in the topic files themselves, and presents the results in a simple tree view.
Background
I have a library which is documented using XML comments. I use NDoc to generate a CHM for the library reference help, but I also have a hand-written "master" CHM file which contains higher-level help. I merge these two help files, and they both contain links to each other. I couldn't find a tool to check these links, so I wrote one :)
This was actually quite easy to write as it is really just a front end for the HtmlHelp library and example viewer by Klaus Weisser. All the details of reading CHM files are handled by the library, which means all I had to do was write the UI and the checking algorithms.
Basically, if you need this tool, it will be invaluable; if you don't, well, thanks for looking.
Using the application
The application is very easy to use - at least I tried to make it that way.
The first thing to do is to open a CHM file. This loads the file and any merged files into the library, and starts to fill out the results tree. You can refresh the file at any time to get back to this state. At this stage, the index, table of contents, and topic files are present, but the links from the topic files are not.
It turns out that getting the links from an HTML file is not that easy. The only article I could find on the subject was on MSDN: Walkthrough: Accessing the DHTML DOM from C#. This basically says to open an IE window, load the file, and then get the links from the DOM. This is slow. And if your CHM file has thousands of pages, this is very slow. However, it is the most accurate method, and is therefore the default.
You can speed things up by orders of magnitude by selecting the "fast parsing" option on the toolbar. This uses regular expressions to search the raw HTML. This works well with simple HTML, but is not perfect, although it does now exclude commented blocks. It is useful as a first pass, but I suggest checking using the slow method before you ship your Help files.
Now you have selected your parsing method, you can start checking by hitting the "Work" toolbar button or pressing Ctrl+W. This process loads and parses all the topic files, and checks all the links found. This process works on the subtree selected in the tree view. By default, the root node is selected, so the whole help collection is checked, but you can select a portion of the tree if you are just interested in that branch. The results are displayed by setting the icon of each tree view item.
Each item in the results has a state, which can be either "unknown", "good", "http", "script", or "broken". The state of the parent items is set according to the state of its child items. So, a parent item is only marked as good if none of its children are marked as broken. This quickly gives you an idea of the correctness of your links, and the detailed metrics are displayed in brackets after each item.
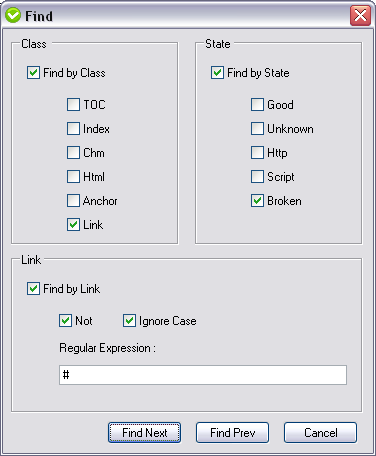
You can then navigate the results using the comprehensive Find feature including regular expressions:
You can also export the results to CSV files. This produces one overall summary file, and one details file for each CHM.
All this can be automated using command line options. These are:
- -f / -fast: select fast mode
- -s / -slow: select slow mode
- -o / -open: open most recently used CHM
- -o:"C:\path\xxx.chm": open specified CHM
- -w / -work: check file
- -x / -export: export reports to default folder
- -x:"C:\path\folder": export to specified folder
- -c / -close: close app
So an example could be: CheckHelpLinks.exe -f -o:"C:\test\test.chm" -w -x -c.
The exit code of the application is zero if there are no errors, and non-zero if there are broken links.
And that's about it. Go and fix your broken links and then check again!
Points of Interest
Reflection Magic
I needed access to a property declared as internal in the library. Obviously, this would normally not be available outside the library, but you can get access to it by using reflection. This is a very powerful practice, but it is not ideal: the library author would be quite right to change his internal implementation in future releases, which would break the client code. So, use at your own risk!
This code comes from the IndexItem.Load method in the ClassesIndex.cs file.
What I wanted to write was this:
CHMFile chmFile = indexItem.ChmFile;
What I actually wrote was this:
Type t = indexItem.GetType();
PropertyInfo p = t.GetProperty( "ChmFile",
BindingFlags.Instance | BindingFlags.NonPublic );
CHMFile chmFile = ( CHMFile ) p.GetValue( indexItem, null );
Accessing the DHTML DOM
The only way I could find of accessing the DOM was by opening a web browser control, loading the HTML, and then getting an IHTMLDocument2 object from the Document property of the control. Apart from being slow, this is a bit tricky, since the loading process is asynchronous. I solved this by setting a flag before beginning the navigation, and waiting until the DocumentComplete event handler cleared the flag. During the wait, I call Application.DoEvents to keep the UI fresh. I don't know how good this is, as it all happens in a dialog box; what I really wanted was to run the dialog box's message loop, but I couldn't find a way of doing this :(. The code is in the DlgBrowser.cs file, if you want to have a look.
The Regular Expressions
These are the RegEx's used in fast mode. There are two RegEx's for both the anchors and links, which look for elements with and without quotes:
- Comment: ^(?<before>.*)(?<comment><!--.*?-->)(?<after>.*)$
- Anchor 1: <\s*A\s[^>]*name\s*=\s*(?<anchor>[^'"].*?)[\s>]
- Anchor 2: <\s*A\s[^>]*name\s*=\s*(?<quote>['"])(?<anchor>.*?)\k<quote>
- Link 1: <\s*(?:A|AREA)\s[^>]*href\s*=\s*(?<url>[^'"].*?)[\s>]
- Link 2: <\s*(?:A|AREA)\s[^>]*href\s*=\s*(?<quote>['"])(?<url>.*?)\k<quote>
References
- CodeProject article: HtmlHelp library and example viewer by Klaus Weisser.
- MSDN article: Walkthrough: Accessing the DHTML DOM from C#.
- SourceForge: NDoc.
- CodeProject article: Full-featured Automatic Argument Parser by Sebastien Lorion.
Acknowledgements
Special thanks to Klaus Weisser for his excellent library and for his help while writing this.
Also, thanks to Ryan Pollack for his help with version 2.
More thanks to Karen Story and Dmitri Posudin for their help with version 3.
History
- Version 3: 2005 September 30
- advanced Find feature
- anchors (bookmarks) now handled
- improved RegEx's for Fast mode
- strips comment blocks in Fast mode
- results export to CSV file
- view source of any link directly
- JavaScript links handled separately
- command line options added
- now handles many more formats of links correctly
- new icon
- Version 2: 2005 August 20
- links to CHM files with no 'ms-its' prefix now handled
- links to external (not merged) CHM files now handled
- HTTP links in CHM files now counted separately
- a couple of bug fixes
- Version 1: 2004 August 16
- First release
License
This article, along with any associated source code and files, is licensed under The Code Project Open License.
Contact
If you have any feedback, please feel free to contact me.