![[logo]](/images/SimplyGenius.png)
Simply Genius .NET
Software that makes you smile
Thread Local Storage

|
|
Publicly recommend on Google
|
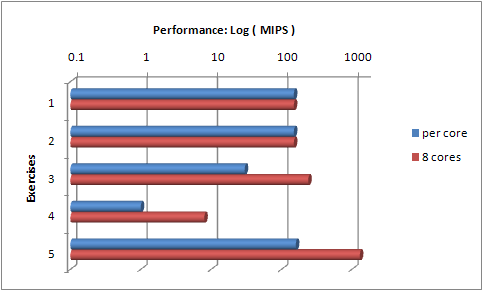
Table of Contents
- Introduction
- Background
- Architecture
- Exercise 1: Blocking the UI thread
- Exercise 2: Freeing the UI thread
- Exercise 3: Introducing concurrency
- Exercise 4: Example of what not to do
- Exercise 5: Using the Thread Local Storage class
- Appendix A: Understanding the Thread Local Storage class
- Appendix B: Comparison with ThreadStaticAttribute
- Appendix C: Comparison with PFX Thread Local Selector
- Conclusion
- References
- History
Introduction
This article has two aims. Firstly, there are a series of five exercises that detail the process of successfully multi-threading a sequential algorithm with timely progress display in the UI. It also provides an implementation of a thread local storage class which can help realise the performance promise of many-core machines.
The exercises start at beginner's level, but even if you are already proficient in concurrent programming I suggest at least skimming though them as they build on one another. If you are short of time, you might like to skip ahead to the description of the new helper class in Appendix A.
The code uses the December 2007 CTP of Microsoft's PFX library to hide some of the plumbing.
Background
Overview
Computers are good at counting, so this is what I chose to use as the test load. Actually, in the last example which is the correct version, only 20% of execution time is spent doing the "work". The rest is spent in the infrastructure, but that's not a problem because it's all work to the CPUs. The interesting part is the relative comparison of the different tests, so the absolute throughput is almost irrelevant.
I say almost, because it is hard to fully appreciate just how fast normal computers are these days. We are talking orders of magnitude here. Clock speeds are around 109 Hz, which is absolutely astounding if you think about it. Light moves at 3 x 108 m/s, so in one clock cycle even light can only travel about a tenth of a metre. Put another way, say you are 2m tall. In the time it takes light to travel from your foot to your eye, a single core can execute 20 instructions. They're fast.
However, even this power is not sufficient for some tasks. Since it looks unlikely that clock speeds will increase significantly, the current hardware trend is towards multi- and many-core machines. Using these machines correctly and efficiently for performance gains is the scenario addressed by this article. It is aimed at people who want to access the scalable performance improvements that concurrent software is capable of on modern machines.
It must be noted that the hardware is still in its infancy. The eight-core box I use is considered high-end at the moment, but the maximum performance increase it can theoretically provide is less than an order of magnitude. If your users have two or even four-core machines, the potential gain is obviously less. I have no doubt that many-core machines are coming, but they won't be here tomorrow. This is, I believe, the reason why support from library providers, in particular Microsoft, is only now beginning to emerge.
Writing correct and efficient concurrent software is not easy at the moment
and I see no evidence of any substantial change on the horizon.
It requires both knowledge and intelligence, but also a diligent approach.
Do not expect to add .AsParallel() and magically reach your goals.
This article walks you through the thought processes required to take advantage of
your users' hardware and I hope it will provoke more questions than provide answers.
PFX
Microsoft's Parallel Extensions library is used to simplify the code by removing the thread control code. This is pretty much all it does at the moment, but it is actually quite good at it. My first impression of this library was disappointment that it didn't go further, but it is useful if you don't expect too much from it. Also, remember that at the time of writing, it is just an early CTP.
Hardware
I tested this application on four boxes:
- 2 cores: Dual Athlon running Server 2003 R2
- 2 cores: Athlon 64 X2 running Server 2003 R2 x64
- 2 cores: Core 2 Duo running Vista Ultimate x64
- 8 cores: Dual Quad-core Xeons running XP Pro x64
The relative performance of the tests were all consistent. The quoted performance metrics are from the 8-core box.
Architecture
TestAttribute
The five test classes that make up the exercise are decorated with this custom attribute.
It has Index and Name properties that identify the test.
TestInfo
This class holds information about each test class and can instantiate them.
It also has some static members that search the assembly using reflection
to build a full list of tests that is used by the UI.
It also has a couple of DependencyProperties that hold
the latest test results, again for use by the UI.
Controller
This class takes a TestInfo and creates an instance of the test class,
which are all derived from TestBase.
It starts the test and records the elapsed time until it is finished.
It then calculates the results and stores them in the TestInfo
instance for display in the UI.
It also holds the calculation of the current percentage progress completed during the test run.
TestBase
This is the base class for the five tests in the exercise.
It implements all the common functionality, including creating threads, running them
and firing the Finished event when they complete.
Factor
Each test class overrides this virtual property to set the number of iterations to perform.
Because the performance of the tests vary by about three orders of magnitude,
it is necessary to control each one separately so that it executes in a reasonable period of time.
Each test is designed to take a few seconds to complete.
Concrete tests
The five concrete test classes all derive from TestBase.
They override the Work method which is called at the start of the test.
This allows them to set up threads ( in some cases ), and provide the method
that will be called for each iteration.
This method is always called Update, although that is not a requirement.
The Update method generally sets the TestBase.Done property,
which is read by the UI as a percentage via the Controller instance.
The exception is the last example, which only calculates the work done when needed.
User Interface
The user interface is a simple WPF application.
It lists each test on the left and allows you to start one by double-clicking it.
As the test executes, it updates the progress bar at 100 millisecond intervals.
It does this using a System.Threading.Timer.
During a test run, you can cancel by pressing the "STOP" button.
When the test completes, the results are stored and displayed.
The UI is only updated ten times a second because this is all that is required to present the user with enough information. The best way to speed up your application is to make it do less work! Calculating the progress more often would only slow down the application, with no appreciable benefit to the user.
Exercise 1: Blocking the UI thread
This exercise presents the problem: a computationally intensive task being performed on the UI thread.
// do not do this
[Test( 1, "Blocking" )]
partial class TLS1Blocking : TestBase
{
public override bool Block { get { return true; } }
protected override void Work()
{
DoWork( Update );
}
void Update( long i )
{
Done = i;
}
}
This example is definitely not recommended.
It overrides the Block property to return true.
This causes the DoWork method to execute on the calling thread,
which is the UI thread.
That means the UI is blocked until the test completes. Not good.
The Update method just sets Done which is the base class property
used in most of the tests to report back to the UI.
Of course, since the UI is blocked, it cannot update itself, so it's a bit pointless.
Except that the compiler doesn't know that and so can't optimise out the assignment.
So, it does give a good base data point. This test executes at about 150 MIPS ( million iterations per second ) on my machine. This is the value against which all the other tests are compared.
Exercise 2: Freeing the UI thread
The aim in this exercise is to make the UI responsive again.
// recommended sequential pattern
[Test( 2, "Sequential" )]
partial class TLS2Sequential : TestBase
{
protected override void Work()
{
DoWork( Update );
}
void Update( long i )
{
Done = i;
}
}
This is the same as #1, except that it does not override the Block property.
The default value is false, which causes a thread to be spun off by the base class
to execute the Work method:
new Thread( new ThreadStart( WorkMaster ) ) { IsBackground = true }.Start();
This basically means that the UI thread is only responsible for creating the new thread and then returns to its own duties as it should. So the UI is free to keep itself up to date and properly report the progress of the test. This technique is also used in all the subsequent tests.
The Work method does not create any more threads,
so the iterations are performed on the single master thread.
This is very similar to #1, except that the UI is updated properly.
It should be no surprise, then, that this test also executes at about 150 MIPS.
Exercise 3: Introducing concurrency
This exercise will attempt to use all the available cores.
// do not do this
[Test( 3, "Wrong" )]
class TLS3Wrong : TestBase
{
public override bool Multithreaded { get { return true; } }
protected override void Work()
{
Parallel.Do( CreateActions( Update ) );
}
void Update( long i )
{
Done = i * Glob.CoreCount;
}
}
We have changed a couple of things in this test:
Firstly, we have overridden the Multithreaded property to return true.
This tells TestBase that we are going to do work on every core in the machine,
which allows it to properly report the total progress.
Again, this is also set in all subsequent tests.
The second change is to the Work method, which initialises the test.
Parallel.Do is a method provided by Microsoft's PFX library.
It just creates a thread for each physical core on the client machine and uses them to run
the provided Actions.
The CreateActions method is in the base class
and creates an array of identical Actions to fill the available cores.
So this Work method sets up 8 threads on my 8 core machine.
The last change is to the Update method.
Glob.CoreCount is a cache of the System.Environment.ProcessorCount property,
which is usually the number of cores in the machine.
It is cached because it is quite slow to fetch.
Because we have told the base class that this test is multi-threaded,
we have to multiply by the number of cores so that the percent progress is reported to be 100% when finished.
This is a bit of a cheat. We now have 8 threads all counting up in steps of 8, so each thread is reporting 8 times it's actual progress. The final result will be correct, but if you run this on a multi-core machine, you will see the progress bar in the UI jump around because the different threads run at different speeds. So this test does not exhibit correct behaviour.
When you run multiple threads, you cannot expect each thread to do the same amount of work in the same time. The kernel is responsible for allocating time slices to each thread. The algorithm and physical effects are so complicated that this is essentially a non-deterministic process. For example, the cores may not be all running at the same speed all the time. If you put pressure on the machine, the CPUs will heat up and when they get too hot, they slow themselves down to prevent permanent physical damage. Also, there is always something else running on your system, even if it is only the OS itself. This causes contention for resources in an effectively random manner. All these effects combined mean that you cannot predict how fast a particular thread will run.
When run, this test performs at best at about 30 MIPSPC ( million iterations per second per core ). However, because it is using all 8 cores, this equates to about 240 MIPS overall, which is roughly double the performance of the sequential algorithm.
That's not great though; each core is running at a fifth the base speed.
This is because the threads are blocking each other when writing to the shared Done property.
The explanation is a bit complicated.
Just take on board that shared state is a performance pitfall.
This result has to do with memory models. A strong memory model guarantees that the actual instructions executed by the CPUs are more like what you would expect when looking at the code in a sequential manner. A weaker memory model allows the CPUs to reorder reads and writes as an optimisation technique. The C# memory model is actually quite weak, which makes writing concurrent programs correctly more difficult. All it requires for normal state is that reads and writes appear not to move within a particular thread. However, the x86 memory model is actually stronger, so optimisations that are allowed by C# never actually happen. This is a problem because the Itanium memory model is weaker, so if you test on an x86, you may never see problems that will occur when a user runs your program on an Itanium system.
The contentions when the threads all try to write the Done property are exacerbated
by the x86 memory model.
This basically treats all writes as volatile, meaning that the write has to go through all the CPU caches
to main memory on each write.
This effectively blocks each thread for quite a bit of time, contributing to the 80% performance loss per core.
So, in summary, although this test uses all available horsepower, it is both incorrect and slow.
Exercise 4: Example of what not to do
This exercise will concentrate on making the program correct.
// do not do this
[Test( 4, "Worse" )]
partial class TLS4Worse : TestBase
{
long _Count = 0;
protected override void Work()
{
_Count = 0;
Parallel.Do( CreateActions( Update ) );
}
void Update( long i )
{
Done = Interlocked.Increment( ref _Count );
}
}
The reason the #3 was incorrect was that each thread was writing to the Done property without any
synchronization with the other threads. This will be corrected in this test using the
System.Threading.Interlocked static class.
This will make the program correct, but as we shall see, it is not yet an acceptable solution.
The Interlocked class provides static methods to alter variables as an atomic action.
This means that while the method is executing, it effectively cannot be interrupted by any other
threads that access the same variable. For the Increment method, this prevents the following scenario.
Suppose two threads want to increment a variable. They both read the old value, add one to it and then write the
updated value back to memory.
The two threads do this independentely of each other, on different cores, at exactly the same time.
The problem is that both threads write the same value, so instead of being incremented
twice, the variable has only increased by 1.
So using Interlocked.Increment should work and indeed it does.
The member field _Count is used because you cannot pass a property as a ref parameter.
The write to the Done property is a race condition again, just like #3,
but the value written will be correct enough in this case.
A gold star to the first person to work out why it is still not absolutely correct.
However, considering performance, we shouldn't expect any improvements over #3.
In fact, this test performs much worse because of the extra work and contentions caused by the
Interlocked.Increment call.
The results are about 1 MIPSPC, which on 8 cores gives 8 MIPS overall.
You might realise at this point that using the Interlocked methods in a tight loop is not a good idea.
Although you can make your program execute correctly, performance will suffer.
The lesson to learn here is that shared state is a performance pitfall, even if you can make the execution correct. While this test is correct enough and uses all the available cores, it's performance is about an order of magnitude worse than the sequential algorithm even on an 8 core machine. We can do better.
Exercise 5: Using the Thread Local Storage class
This exercise will solve the performance problems, while keeping the code correct.
// this is the recommended strategy
[Test( 5, "Right" )]
partial class TLS5Right : TestBase
{
public override long Done
{
get
{
var tls = TLS;
if ( tls == null ) return 0;
return tls.Results.Sum( s => s.Done );
}
}
protected override void Work()
{
TLS = new Common.TLS<State>();
Parallel.Do( CreateActions( Update ) );
}
void Update( long i, State state )
{
++state.Done;
}
}
partial class TestBase
{
protected class State
{
public long Done = 0;
}
}
In this test, we introduce a class called TLS, standing for Thread Local Storage.
This class does two things.
Firstly, it provides each thread with its own instance of the State class generic parameter.
There are other ways to do this, but it also provides a second function.
It exposes a Results property of type ICollection<State>
which gives any thread access to all the instances of State that have
been created for all threads.
The Update method takes a State parameter,
which is unique for each thread.
This means that there is no shared state and each thread can update the members of the
provided State instance without worrying about any other threads.
This is a very powerful technique.
It essentially removes the requirement for any synchronisation in the inner work loop.
If you remember, the UI thread accesses the current work completed percentage ten times a second.
This is extremely slow from the point of view of the hardware, while being fast enough for the user.
So this test defers the calculation to when it is needed by overriding the Done property.
It could do the calculation on every iteration on every thread, but that would be a huge increase in
the amount of work, for absolutely no gain.
Remember again that the fastest work is no work at all.
So, we've removed the blocking synchronisation from the inner loop, how does it perform? We're up to 160 MIPSPC, which is actually a bit faster than the sequential algorithm. But we're also running on 8 cores, giving 1,300 MIPS overall. So on an 8 core machine, we have achieved about a factor of 8 performance improvement. Not bad. Also, this algorithm is correct and will scale with as many cores as you can give it.
Appendix A: Understanding the Thread Local Storage class
Here is the implementation of the TLS class in its entirety:
using System;
using System.Collections.Generic;
using System.Threading;
namespace Common
{
public class TLS<DATA> where DATA : class, new()
{
volatile Dictionary<int, DATA> _List =
new Dictionary<int, DATA>();
volatile object _Key = new object();
public DATA Current
{
get
{
int thread = Thread.CurrentThread.ManagedThreadId;
DATA tls = null;
if ( !_List.TryGetValue( thread, out tls ) )
{
lock ( _Key )
{
if ( !_List.TryGetValue( thread, out tls ) )
{
tls = new DATA();
Dictionary<int, DATA> list =
new Dictionary<int, DATA>( _List );
list.Add( thread, tls );
Thread.MemoryBarrier();
_List = list;
}
}
}
return tls;
}
}
public ICollection<DATA> Results
{
get
{
lock ( _Key ) return new List( _List.Values );
}
}
}
}
There's not much code, but it does some very useful things and is as bulletproof as I could make it.
The state is a collection of the generic type parameter <DATA>.
One instance of this class is created for each ManagedThreadId.
The collection is a Dictionary<int, DATA> called _List.
The _Key object is a local synchronisation object;
The Current property creates or retrieves the DATA instance for the thread on which it is called.
It does this using the "double-check locking" pattern.
This means that after the instance has been created for a thread, no locking is required to access that instance.
This makes fetching the instance quite fast, but even so, it should be used as infrequently as possible.
The locking part of the get method is fairly standard and well documented on the web.
The only change I have made is to add a call to Thread.MemoryBarrier.
Experts disagree on whether this is necessary, so I have included it just to be sure.
The problem is that the writes required to instantiate the DATA instance may possibly move after
the instruction that sets the _List field.
This could mean that another thread might use its DATA instance before it is completely instantiated.
I don't think this can happen with this implementation, as the ManagedThreadId should
be unique for a thread.
So the lock statement, which is a memory barrier,
must complete before the instance is returned to the calling thread.
If the call is redundant,
we have lost very little because this execution path should only be taken once per thread.
I have even heard that Thread.MemoryBarrier is a NOP on x86 systems.
The Results property gives access to all the instances of DATA created for all threads
in a thread-safe wrapper.
It must return a new collection of the instances as it does not know how long the calling thread will keep the return value.
As you can see, it locks every time and so should not be called too often.
This is ususally not a problem as the results will probably be used in the UI and that only has to run quickly enough for the user,
which is a glacial pace for the hardware.
Appendix B: Comparison with ThreadStaticAttribute
When the ThreadStaticAttribute is applied to a static field, it gets a new value for each thread.
In that sense it seems to do the same as the TLS class.
Also, in stress tests, it performed about twice as fast as TLS.Current.
However, as far as I know, there is no way to access the instances created for other threads.
This means that you cannot generate summary or result data across all threads.
This is the problem that the TLS class solves.
Appendix C: Comparison with PFX Thread Local Selector
Some of the PFX methods allow you to select thread-local data, for example:
partial class Parallel
{
public static void ForEach<TSource, TLocal>(
IEnumerable<TSource> source,
Func<TLocal> threadLocalSelector,
Action<TSource, int, ParallelState<TLocal>> body,
Action<TLocal> threadLocalCleanup
)
{...}
}
This has the same problem as the ThreadStaticAttribute above, in that you cannot access another
thread's private instance.
The threadLocalCleanup Action mitigates this slightly by giving you
a chance to use the results just before the thread completes.
However, you still can't access it while the thread is executing.
You can combine the two techniques, like this:
var tls = new TLS<State>();
Parallel.ForEach(
collection,
() => tls.Current,
( data, index, parallelState ) =>
{
State state = parallelState.ThreadLocalState;
...
} );
Conclusion
I hope that this article has answered some of your questions about concurrent programming.
I have not gone into too much depth in order to limit its length.
My goal in writing this was really to generate interest in the subject
and, as I said at the beginning, to provoke more questions.
You may, of course, use the TLS class subject to the license below.
Thanks for reading.
References
MS Parallel Computing Developer Center [^]
History
- 2008 - 05 - 11: First version.
License
This article, along with any associated source code and files, is licensed under The Code Project Open License.
Contact
If you have any feedback, please feel free to contact me.