![[logo]](/images/SimplyGenius.png)
Simply Genius .NET
Software that makes you smile
WebBrowserEx: WinForms WebBrowser + HTTP Server

|
|
Publicly recommend on Google
|
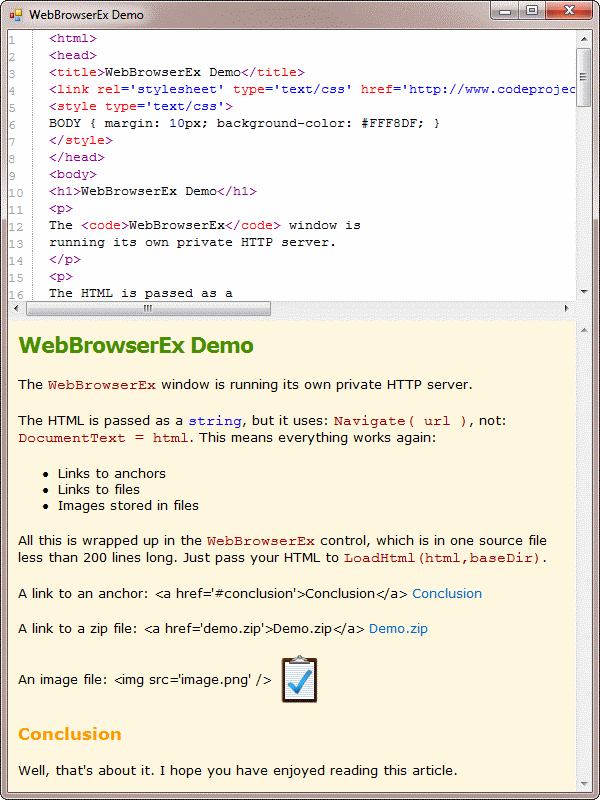
Table of Contents
Introduction
This is a short article that fixes the problems with using the
WinForms WebBrowser.DocumentText property.
I have written a tiny HTTP server and have wrapped it in a class derived from WebBrowser.
This means that instead of setting the WebBrowser.DocumentText property with your HTML,
you can call WebBrowser.Navigate( [server url] )
and let the server provide your HTML and supporting files just like a real website.
This makes the WebBrowser control much happier.
Background
I have been using a WinForms WebBrowser control as the display in a HTML authoring application.
The HTML changes with every keystroke, so I need to send it to the control dynamically.
I was using the WebBrowser.DocumentText property,
but this was causing all sorts of little problems.
Problems
Relative Paths
Firstly, the HTML had <img> and <a> tags
that pointed at files on disk with paths relative to the saved HTML document.
This shows an example directory structure:
+ WebBrowserEx // parent directory
+ Article // base directory
+ WebBrowserEx.html // html file
+ WebBrowserEx // subdirectory
+ demo.png // image file
+ src.zip // zip file
+ WebBrowserEx // code directory
+ WebBrowserEx.sln // solution file
+ ...
So the HTML would look like this:
<img src='WebBrowserEx/demo.png'>
<a href='WebBrowserEx/src.zip'>
I fixed this by modifying the HTML that was sent to the control
by adding a <base> tag to the <head> element:
<base href='file:///C:/...path.../WebBrowserEx/Article/'>
This fixed the images, but for some reason ( security? ) not the links. This was the best compromise workaround I could find at the time.
Internal Links
The other problem was with anchors. The HTML usually had a "Table of Contents", which was basically a list of links to anchors:
...
<h2>Table of Contents</h2>
<ul>
<li><a href='#Introduction'>Introduction</a></li>
...
<h2><a name='Introduction'>Introduction</a></h2>
...
With the <base> tag needed to show the images,
the anchor links were combined to include the file:// protocol,
giving URL's like this:
file:///C:/...path.../WebBrowserEx/Article/#Introduction
These don't point to the correct locations and so none of the internal links worked.
Solution
So, all in all, using WebBrowser.DocumentText caused unacceptable compromises
about which tags worked and which didn't.
Having accepted that the WebBrowser control was not ever going to be happy
without a proper HTTP server,
I wondered how difficult it would be to write one.
It turned out that it was ridiculously easy.
The .NET framework has included the difficult part since version 2.0: implementing the HTTP/1.1 protocol.
The relevant classes are in the System.Net namespace in System.dll:
class HttpListener // handles socket-level connections
class HttpListenerContext // holds the request and response objects
class HttpListenerRequest // parses the request into properties
class HttpListenerResponse // compiles the response into valid HTTP
Stream response.OutputStream // holds the response entity in binary
All I had to do was use the URL to either return the HTML string or find a file on disk
and write them as binary to the OutputStream.
OK, I did also have to set a few header properties, for example ContentType,
but really: it's amazing how much knowledge is coded in the Framework!
Using the Code
If your requirements match mine, all you have to do is replace your
WebBrowser instance with a WebBrowserEx
and call LoadHtml( string html, string baseDirectory )
instead of setting DocumentText. That's it.
The basic server code is very simple.
If your requirements are slightly different, all you need to do is change where you get the binary data.
For instance, if your images are stored as resources in your assembly,
you can serve them from there.
No more funny URI's and Base64 encoding!
Full Source
I wouldn't normally dump the entire source in the article itself, but since it's only 200 lines in total:
using System;
using System.Diagnostics;
using System.IO;
using System.Net;
using System.Net.Mime;
using System.Text;
using System.Threading;
namespace Common
{
public class WebBrowserEx : System.Windows.Forms.WebBrowser
{
string _Html = String.Empty;
string _BaseDirectory = String.Empty;
public void LoadHtml( string html, string baseDirectory )
{
if ( SynchronizationContext.Current != _UI )
throw new ApplicationException(
"WebBrowserEx.LoadHtml must be called on the UI thread." );
InitServer();
_Html = html;
_BaseDirectory = baseDirectory;
if ( _Server == null ) return;
_Server.SetHtml( html, baseDirectory );
Navigate( _Server.Url );
}
SynchronizationContext _UI = null;
bool _TriedToStartServer = false;
Server _Server = null;
public WebBrowserEx()
{
_UI = SynchronizationContext.Current;
}
void InitServer()
{
if ( _TriedToStartServer ) return;
_TriedToStartServer = true;
_Server = new Server();
}
public class Server
{
string _Html = String.Empty;
string _BaseDirectory = String.Empty;
public void SetHtml( string html, string baseDirectory )
{
_Html = html;
_BaseDirectory = baseDirectory;
}
public Uri Url { get { return new Uri(
"http://" + "localhost" + ":" + _Port + "/" ); } }
HttpListener _Listener = null;
int _Port = -1;
public Server()
{
var rnd = new Random();
for ( int i = 0 ; i < 100 ; i++ )
{
int port = rnd.Next( 49152, 65536 );
try
{
_Listener = new HttpListener();
_Listener.Prefixes.Add( "http://localhost:" + port + "/" );
_Listener.Start();
_Port = port;
_Listener.BeginGetContext( ListenerCallback, null );
return;
}
catch ( Exception x )
{
_Listener.Close();
Debug.WriteLine( "HttpListener.Start:\n" + x );
}
}
throw new ApplicationException( "Failed to start HttpListener" );
}
public void ListenerCallback( IAsyncResult ar )
{
_Listener.BeginGetContext( ListenerCallback, null );
var context = _Listener.EndGetContext( ar );
var request = context.Request;
var response = context.Response;
Debug.WriteLine( "SERVER: " + _BaseDirectory + " " + request.Url );
response.AddHeader( "Cache-Control", "no-cache" );
try
{
if ( request.Url.AbsolutePath == "/" )
{
response.ContentType = MediaTypeNames.Text.Html;
response.ContentEncoding = Encoding.UTF8;
var buffer = Encoding.UTF8.GetBytes( _Html );
response.ContentLength64 = buffer.Length;
using ( var s = response.OutputStream ) s.Write( buffer, 0, buffer.Length );
return;
}
var filepath = Path.Combine( _BaseDirectory,
request.Url.AbsolutePath.Substring( 1 ) );
Debug.WriteLine( "--FILE: " + filepath );
if ( !File.Exists( filepath ) )
{
response.StatusCode = ( int ) HttpStatusCode.NotFound; // 404
response.StatusDescription = response.StatusCode + " Not Found";
response.ContentType = MediaTypeNames.Text.Html;
response.ContentEncoding = Encoding.UTF8;
var buffer = Encoding.UTF8.GetBytes(
"<html><body>404 Not Found</body></html>" );
response.ContentLength64 = buffer.Length;
using ( var s = response.OutputStream ) s.Write( buffer, 0, buffer.Length );
return;
}
byte[] entity = null;
try
{
entity = File.ReadAllBytes( filepath );
}
catch ( Exception x )
{
Debug.WriteLine( "Exception reading file: " + filepath + "\n" + x );
response.StatusCode = ( int ) HttpStatusCode.InternalServerError; // 500
response.StatusDescription = response.StatusCode + " Internal Server Error";
response.ContentType = MediaTypeNames.Text.Html;
response.ContentEncoding = Encoding.UTF8;
var buffer = Encoding.UTF8.GetBytes(
"<html><body>500 Internal Server Error</body></html>" );
response.ContentLength64 = buffer.Length;
using ( var s = response.OutputStream ) s.Write( buffer, 0, buffer.Length );
return;
}
response.ContentLength64 = entity.Length;
switch ( Path.GetExtension( request.Url.AbsolutePath ).ToLowerInvariant() )
{
//images
case ".gif": response.ContentType = MediaTypeNames.Image.Gif; break;
case ".jpg":
case ".jpeg": response.ContentType = MediaTypeNames.Image.Jpeg; break;
case ".tiff": response.ContentType = MediaTypeNames.Image.Tiff; break;
case ".png": response.ContentType = "image/png"; break;
// application
case ".pdf": response.ContentType = MediaTypeNames.Application.Pdf; break;
case ".zip": response.ContentType = MediaTypeNames.Application.Zip; break;
// text
case ".htm":
case ".html": response.ContentType = MediaTypeNames.Text.Html; break;
case ".txt": response.ContentType = MediaTypeNames.Text.Plain; break;
case ".xml": response.ContentType = MediaTypeNames.Text.Xml; break;
// let the user agent work it out
default: response.ContentType = MediaTypeNames.Application.Octet; break;
}
using ( var s = response.OutputStream ) s.Write( entity, 0, entity.Length );
}
catch ( Exception x )
{
Debug.WriteLine( "Unexpected exception. Aborting...\n" + x );
response.Abort();
}
}
}
}
}
Conclusion
Well, that's about it. I hope you have enjoyed reading this article and can use this technique in your code.
License
This article, along with any associated source code and files, is licensed under The Code Project Open License.
Contact
If you have any feedback, please feel free to contact me.